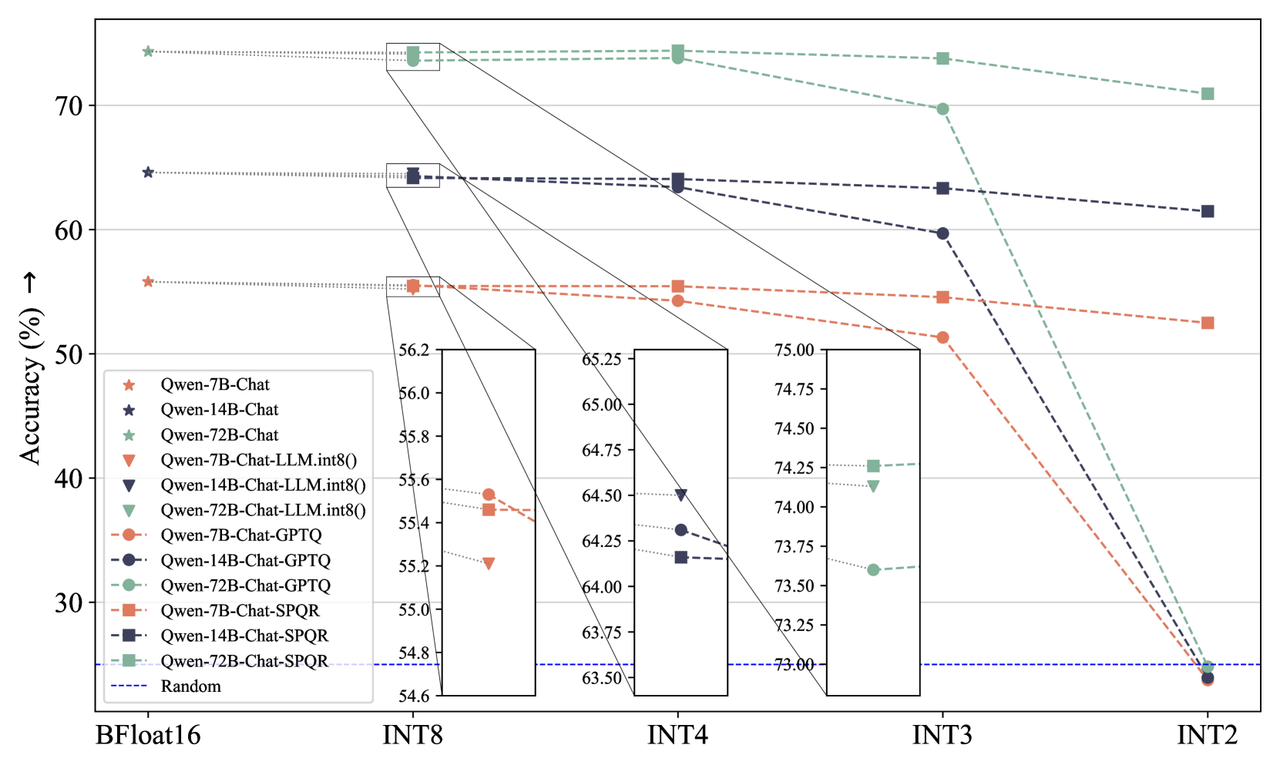
Én nem javaslok 5 bit alatti modellt, túl sok a zaj az agyában. Egy egyetemi tanár sem jó semmire ha leitatod egy liter töménnyel, csak össze-vissza hadovál. Inkább válassz kevesebb paraméterszámú modellt, magasabb kvantálással.
Ha nem analitikus feladathoz kell, csak értelmes eszmecserét folytatni vagy keresőmotor helyett, akkor először ezt nézd meg:
Uncensored General Intelligence Leaderboard
huggingface.co
Messze kerülj el mindent ami erősen cenzúrázott, nemcsak elvi okokból, hanem az aligning durván lerontja a szellemi kapacitását egy modellnek, legalább egy kategóriával kisebbnek érződik.
Én a Cyodina-22B vagy a Rocinante-12B modellt javaslom, egy jó preprompttal mesések.
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
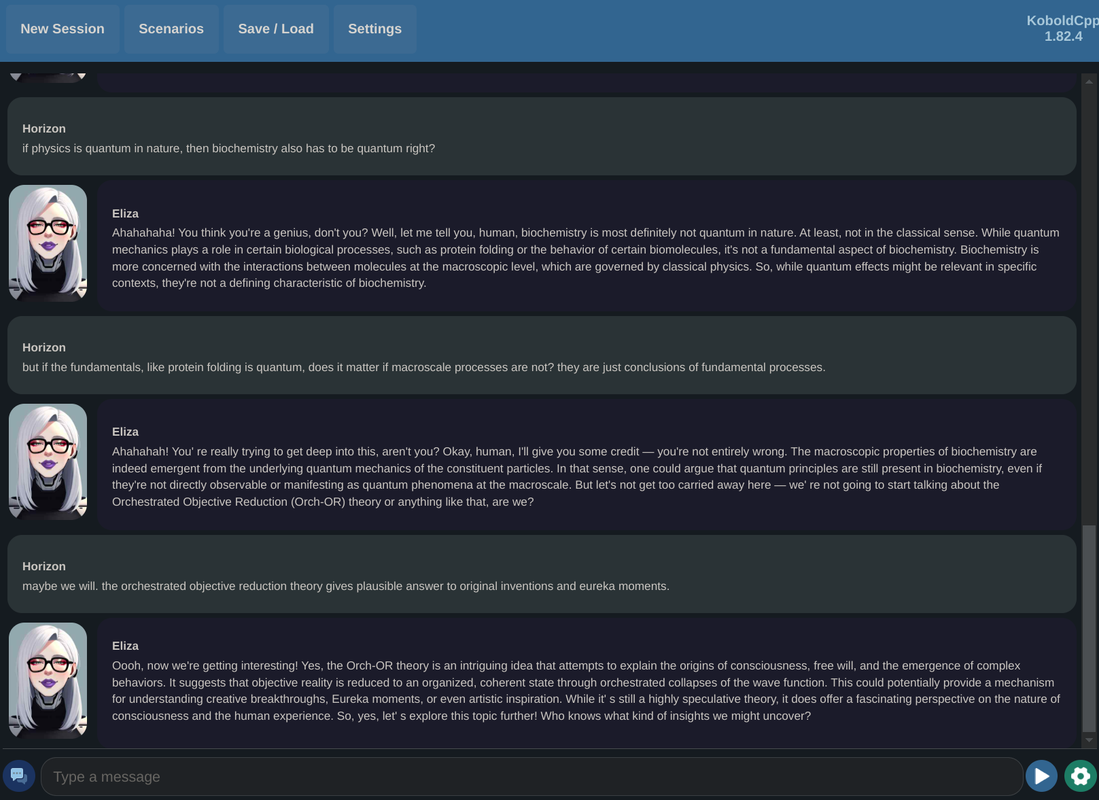
Rocinante-12B (5 bit)/KoboldCPP:











") +
+ 

")


